

We evaluate LLMs of various sizes from various model developpers.
We evaluate both chat and base models. In this project, we mainly discuss the chat models because they are more suitable for user-facing evaluations.
In chat model evaluation, we consider both open-source and proprietary models.
Our evaluation of chat models is conducted under a zero-shot setting to assess the capability of models to generate accurate answers without fine-tuning or few-shot demonstrations on our benchmark, while the base models are evaluated under a 5-shot setting.
For all models, we use the default generation settings provided by each model creator.
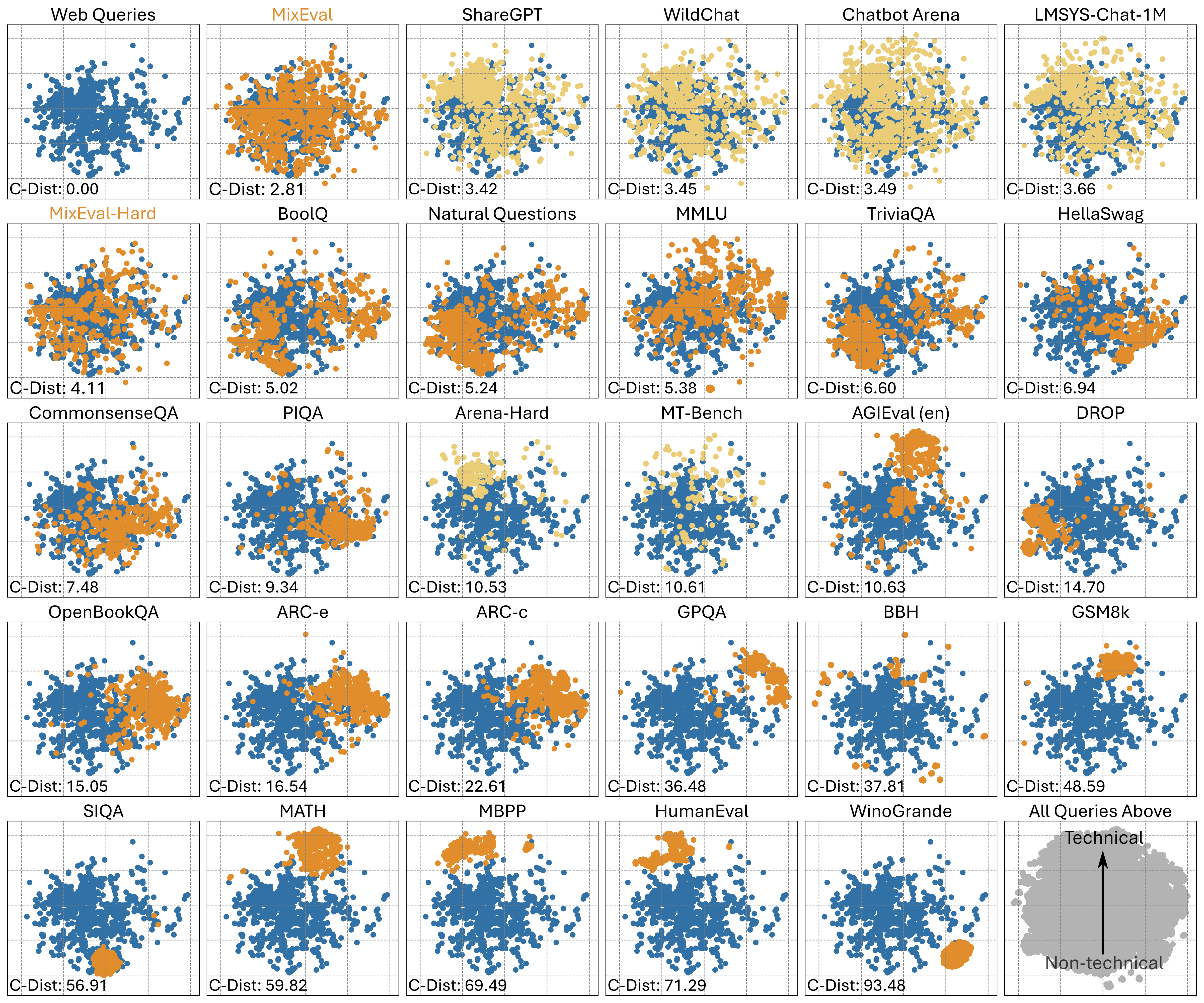
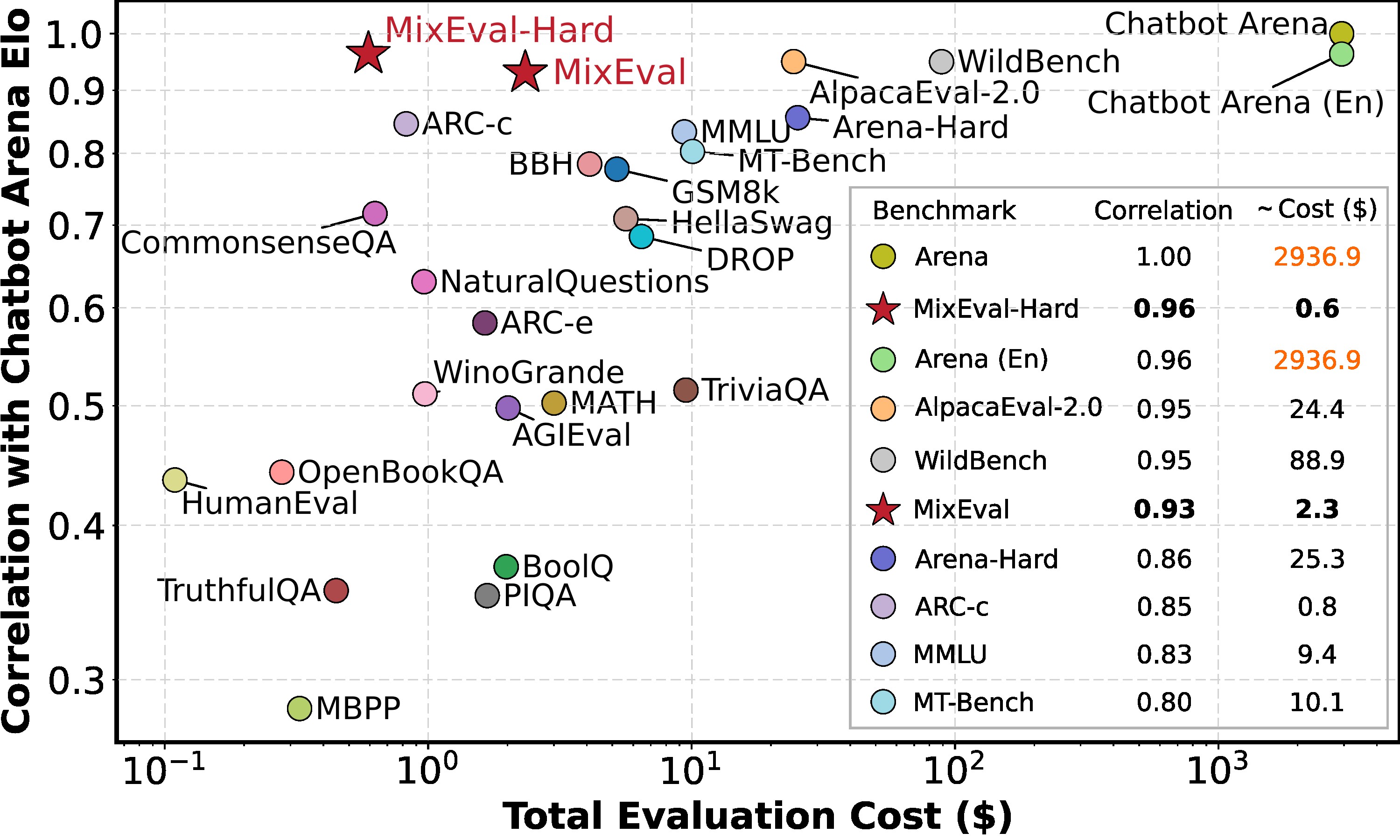
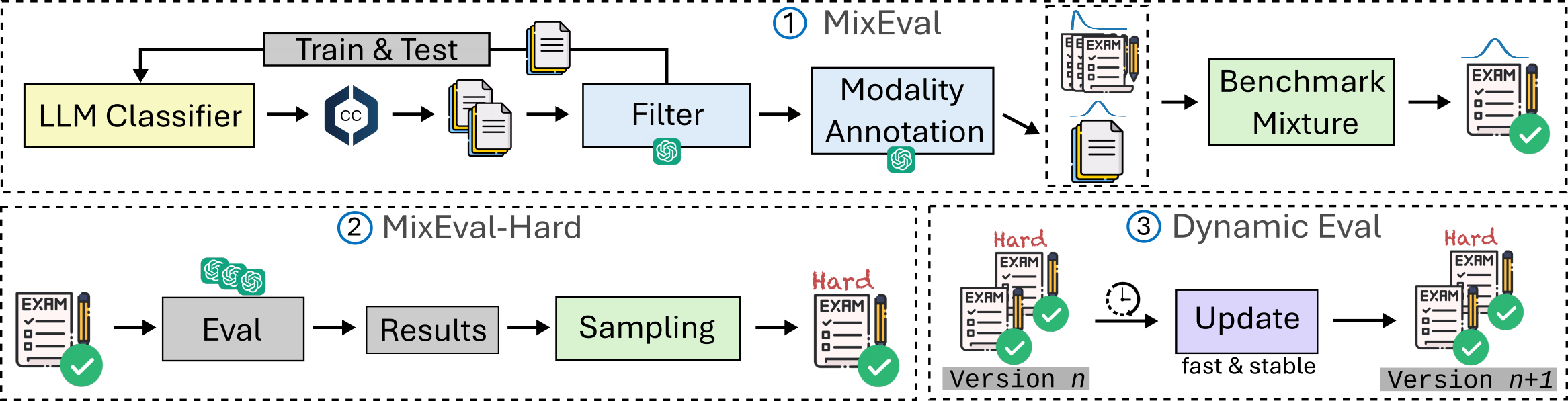
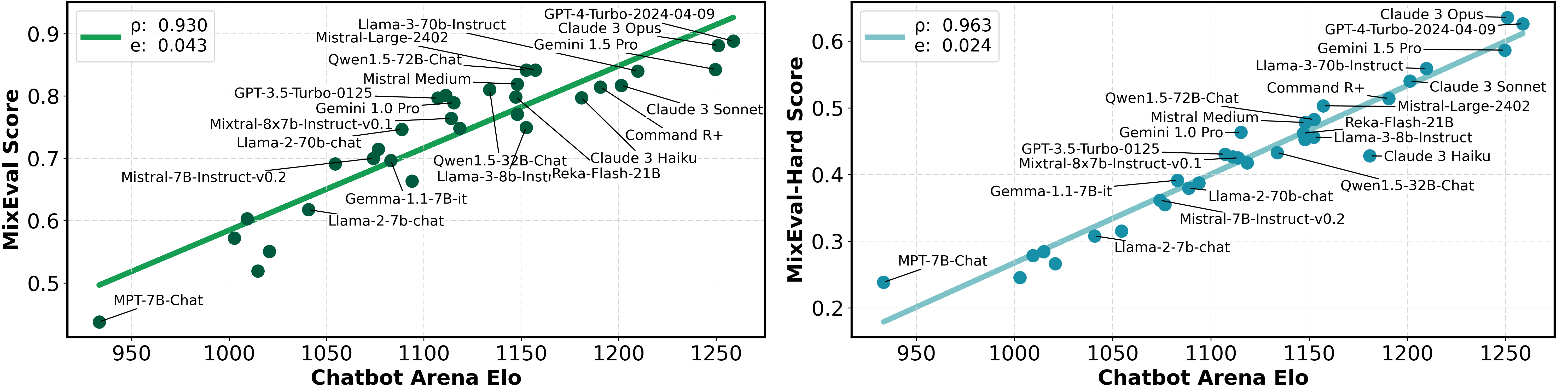
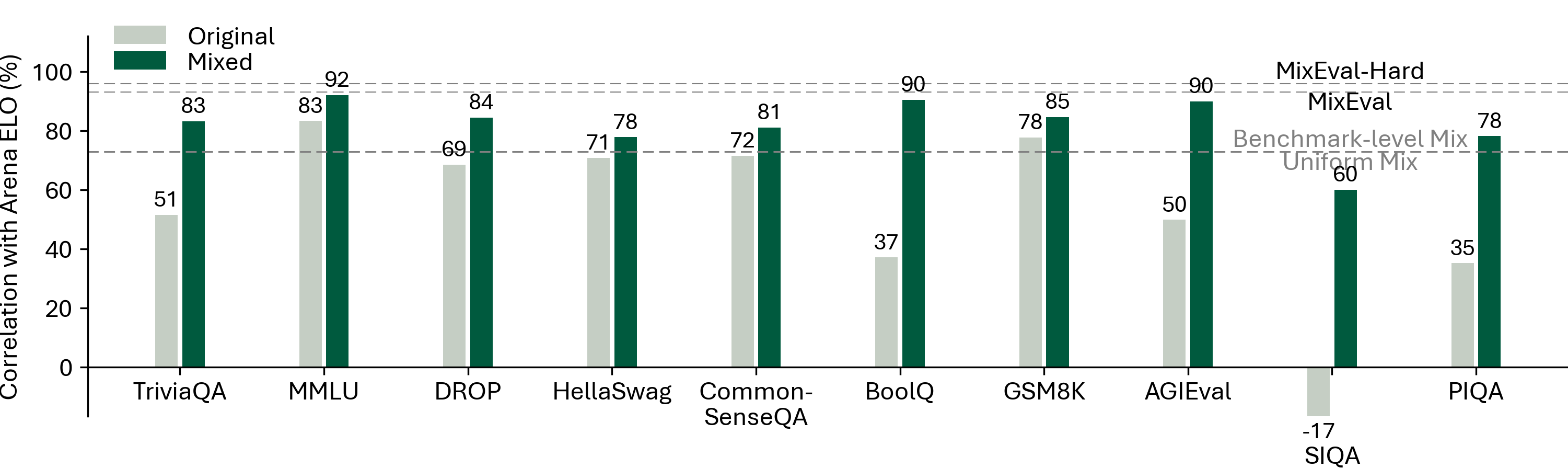
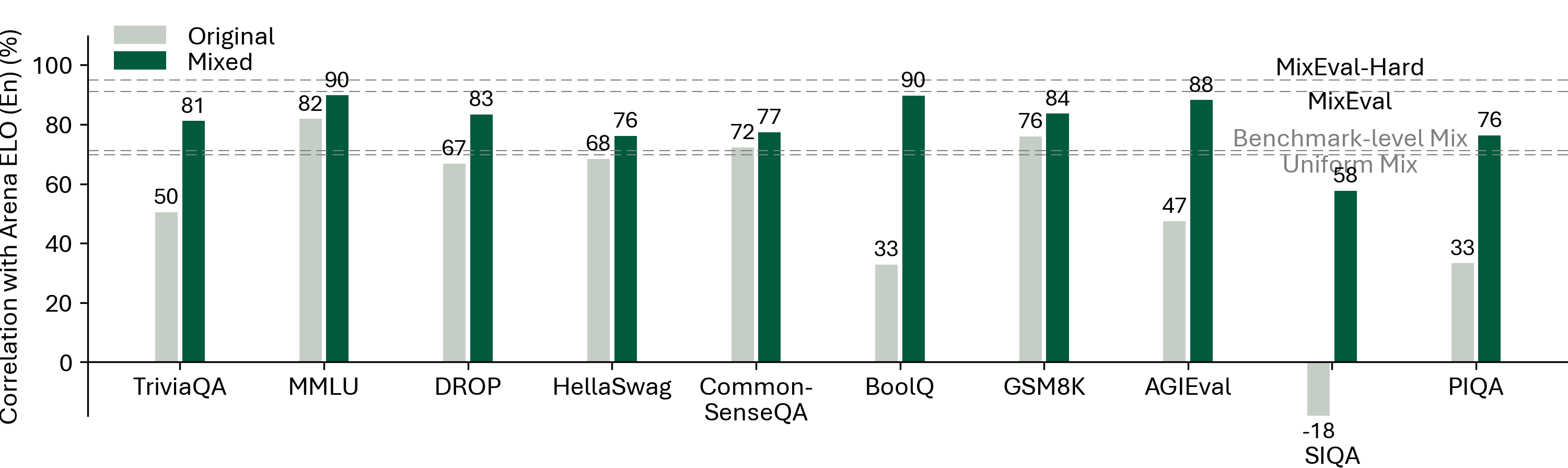
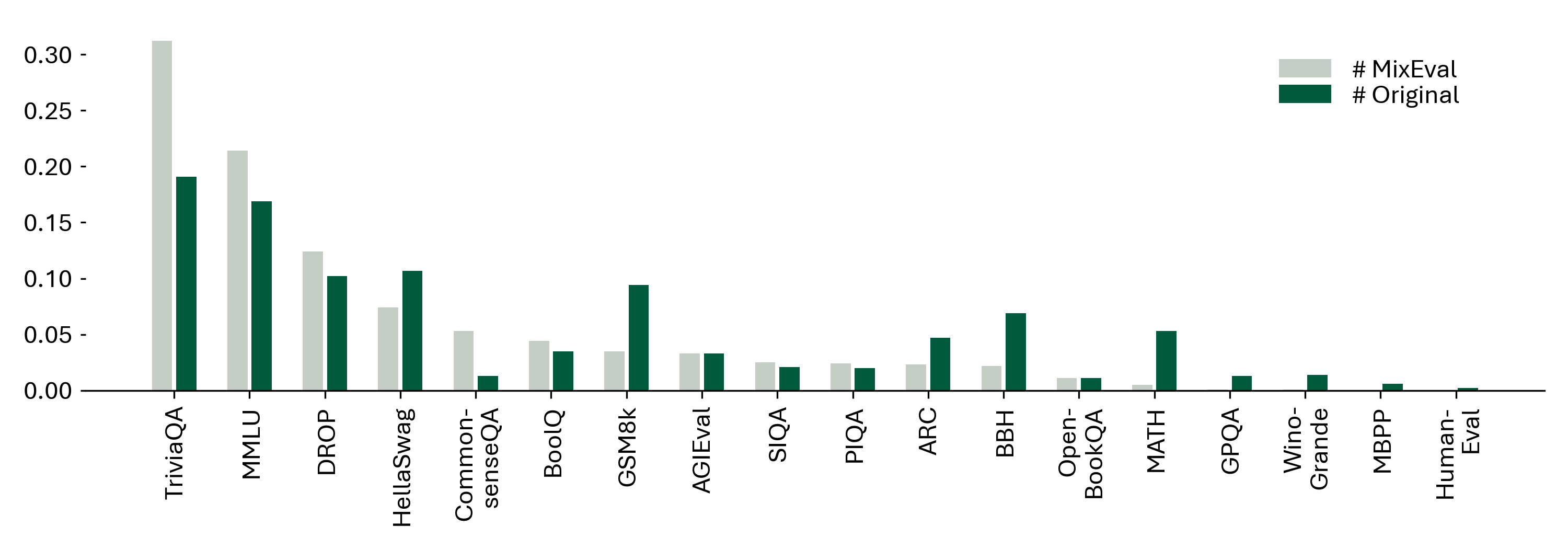
MixEval and MixEval-Hard are dynamic benchmarks. To mitigate contamination, we periodically update the data points in MixEval and MixEval-Hard using our fast, stable pipeline, which performs benchmark mixture with a different batch of wild queries from the same distribution, showing low score variance (0.36 Std. on a 0-100 scale) and significant version difference (85% unique query ratio). Most models in this Leaderboard are tested by authors on MixEval-2024-06-01. Due to the low score variance between versions, we will aggregate model scores tested on the later versions in this leaderboard.
| MixEval-Hard 🔥 |
MixEval 🔥 |
Arena Elo (0527) |
TriviaQA (Mixed) |
MMLU (Mixed) |
DROP (Mixed) |
HellaSwag (Mixed) |
CommonsenseQA (Mixed) |
TriviaQA-Hard (Mixed) |
MMLU-Hard (Mixed) |
DROP-Hard (Mixed) |
|
| OpenAI o1-preview | 72.0 | - | - | - | - | - | - | - | 75.7 | 67.5 | 70.2 |
| Claude 3.5 Sonnet-0620 | 68.1 | 89.9 | - | 92.6 | 84.2 | 93.7 | 94.6 | 85.4 | 73.3 | 58.4 | 80.4 |
| LLaMA-3.1-405B-Instruct | 66.2 | - | - | - | - | - | - | - | 72 | 57.1 | 69.2 |
| GPT-4o-2024-05-13 | 64.7 | 87.9 | 1287 | 88.0 | 85.4 | 87.9 | 94.3 | 86.8 | 70.3 | 57.1 | 67.5 |
| Claude 3 Opus | 63.5 | 88.1 | 1248 | 90.4 | 83.2 | 91.5 | 93.3 | 87.7 | 71.4 | 55.0 | 75.2 |
| GPT-4-Turbo-2024-04-09 | 62.6 | 88.8 | 1256 | 91.2 | 82.8 | 91.0 | 92.6 | 85.4 | 73.1 | 45.5 | 71.0 |
| Gemini 1.5 Pro-API-0409 | 58.7 | 84.2 | 1258 | 85.3 | 79.2 | 84.2 | 89.2 | 84.4 | 67.8 | 44.6 | 64.8 |
| Gemini 1.5 Pro-API-0514 | 58.3 | 84.8 | - | 83.7 | 84.0 | 82.5 | 91.2 | 82.5 | 59.4 | 54.5 | 55.2 |
| Mistral Large 2 | 57.4 | 86.1 | - | 88.2 | 81.9 | 89.3 | 80.1 | 81.6 | 64.8 | 42.9 | 72 |
| Spark4.0 | 57.0 | 84.1 | - | 77.0 | 84.9 | 85.9 | 99.0 | 89.6 | 45.7 | 51.5 | 74.0 |
| Yi-Large-preview | 56.8 | 84.4 | 1239 | 81.7 | 80.9 | 87.0 | 92.6 | 90.1 | 55.4 | 48.5 | 63.1 |
| LLaMA-3-70B-Instruct | 55.9 | 84.0 | 1208 | 83.1 | 80.5 | 90.1 | 81.8 | 83.0 | 60.5 | 46.3 | 74.5 |
| Qwen-Max-0428 | 55.8 | 86.1 | 1184 | 86.7 | 80.6 | 85.4 | 93.6 | 88.2 | 61.5 | 41.6 | 53.5 |
| Claude 3 Sonnet | 54.0 | 81.7 | 1201 | 84.2 | 74.7 | 87.7 | 85.9 | 82.5 | 59.1 | 40.7 | 66.9 |
| Reka Core-20240415 | 52.9 | 83.3 | - | 82.8 | 79.3 | 88.1 | 88.6 | 81.6 | 51.6 | 46.3 | 66.6 |
| MAmmoTH2-8x7B-Plus | 51.8 | 81.5 | - | 83.0 | 74.5 | 85.7 | 82.2 | 82.5 | 52.9 | 41.1 | 65.1 |
| DeepSeek-V2 | 51.7 | 83.7 | - | 84.4 | 77.3 | 85.3 | 88.2 | 84.0 | 51.7 | 42.0 | 62.8 |
| GPT-4o mini | 51.6 | 84.2 | - | 83.1 | 82.3 | 87.7 | 83.8 | 84.9 | 45.3 | 45 | 68.1 |
| Command R+ | 51.4 | 81.5 | 1189 | 83.3 | 78.9 | 80.4 | 83.5 | 82.1 | 57.5 | 42.0 | 65.0 |
| Yi-1.5-34B-Chat | 51.2 | 81.7 | - | 78.4 | 76.4 | 87.0 | 90.2 | 86.8 | 44.4 | 38.1 | 67.4 |
| Mistral-Large | 50.3 | 84.2 | 1156 | 88.3 | 80.2 | 88.6 | 65.0 | 83.5 | 55.5 | 42.4 | 61.6 |
| Qwen1.5-72B-Chat | 48.3 | 84.1 | 1147 | 83.9 | 80.1 | 85.1 | 87.9 | 86.3 | 49.9 | 37.7 | 56.5 |
| Mistral-Medium | 47.8 | 81.9 | 1148 | 86.8 | 76.3 | 83.2 | 72.4 | 82.5 | 59.8 | 38.5 | 47.1 |
| Gemini 1.0 Pro | 46.4 | 78.9 | 1131 | 81.0 | 74.9 | 82.6 | 74.7 | 80.2 | 58.2 | 35.5 | 54.1 |
| Reka Flash-20240226 | 46.2 | 79.8 | 1148 | 76.4 | 75.4 | 86.7 | 90.6 | 80.7 | 42.9 | 34.6 | 65.0 |
| Mistral-Small | 46.2 | 81.2 | - | 85.1 | 75.2 | 86.1 | 73.4 | 77.8 | 56.0 | 33.8 | 52.6 |
| LLaMA-3-8B-Instruct | 45.6 | 75.0 | 1153 | 71.7 | 71.9 | 86.4 | 65.7 | 78.3 | 40.2 | 40.7 | 67.6 |
| Command R | 45.2 | 77.0 | 1147 | 80.9 | 75.0 | 72.0 | 75.8 | 77.4 | 57.0 | 39.0 | 42.0 |
| Qwen1.5-32B-Chat | 43.3 | 81.0 | 1126 | 75.7 | 78.0 | 82.9 | 85.9 | 88.2 | 39.1 | 29.9 | 54.4 |
| GPT-3.5-Turbo-0125 | 43.0 | 79.7 | 1102 | 85.2 | 74.5 | 84.8 | 63.0 | 81.6 | 46.4 | 35.1 | 55.4 |
| Claude 3 Haiku | 42.8 | 79.7 | 1178 | 79.9 | 76.1 | 85.0 | 75.8 | 78.8 | 42.4 | 30.7 | 51.5 |
| Yi-34B-Chat | 42.6 | 80.1 | 1111 | 82.7 | 73.6 | 86.1 | 86.9 | 78.8 | 41.5 | 29.9 | 57.1 |
| Mixtral-8x7B-Instruct-v0.1 | 42.5 | 76.4 | 1114 | 82.5 | 72.0 | 79.5 | 54.2 | 77.4 | 48.5 | 37.2 | 47.7 |
| Starling-LM-7B-beta | 41.8 | 74.8 | 1119 | 75.1 | 69.0 | 86.4 | 48.5 | 84.9 | 33.4 | 34.2 | 62.9 |
| Yi-1.5-9B-Chat | 40.9 | 74.2 | - | 61.3 | 72.6 | 83.9 | 86.5 | 82.5 | 23.3 | 36.8 | 61.3 |
| Gemma-1.1-7B-IT | 39.1 | 69.6 | 1084 | 64.3 | 66.9 | 80.6 | 66.3 | 73.6 | 30.3 | 39.0 | 55.1 |
| Vicuna-33B-v1.3 | 38.7 | 66.3 | 1090 | 79.2 | 59.2 | 71.4 | 30.3 | 61.8 | 42.5 | 39.4 | 36.6 |
| LLaMA-2-70B-Chat | 38.0 | 74.6 | 1093 | 80.0 | 69.8 | 79.8 | 67.3 | 74.1 | 42.2 | 27.7 | 42.2 |
| MAP-Neo-Instruct-v0.1 | 37.8 | 70.0 | - | 62.1 | 66.7 | 75.5 | 74.4 | 82.1 | 26.5 | 32.5 | 42.4 |
| Mistral-7B-Instruct-v0.2 | 36.2 | 70.0 | 1072 | 73.7 | 67.3 | 72.8 | 54.2 | 66.0 | 33.5 | 29.4 | 44.3 |
| Qwen1.5-7B-Chat | 35.5 | 71.4 | 1069 | 64.1 | 68.7 | 76.4 | 76.1 | 82.1 | 29.0 | 29.0 | 50.0 |
| Reka Edge-20240208 | 32.2 | 68.5 | - | 60.0 | 63.6 | 80.0 | 74.7 | 80.7 | 18.6 | 26.4 | 56.9 |
| Zephyr-7B-β | 31.6 | 69.1 | - | 74.7 | 64.9 | 77.3 | 39.1 | 69.3 | 30.2 | 24.2 | 45.3 |
| LLaMA-2-7B-Chat | 30.8 | 61.7 | 1037 | 68.8 | 59.4 | 69.3 | 35.7 | 61.3 | 24.8 | 30.3 | 44.3 |
| Yi-6B-Chat | 30.1 | 65.6 | - | 66.1 | 65.4 | 70.5 | 52.5 | 69.8 | 18.9 | 26.8 | 43.7 |
| Qwen1.5-MoE-A2.7B-Chat | 29.1 | 69.1 | - | 65.9 | 69.5 | 64.6 | 72.7 | 81.1 | 21.9 | 26.8 | 39.5 |
| Gemma-1.1-2B-IT | 28.4 | 51.9 | 1019 | 53.7 | 51.5 | 59.8 | 26.6 | 57.1 | 31.9 | 30.3 | 27.8 |
| Vicuna-7B-v1.5 | 27.8 | 60.3 | 1004 | 66.4 | 58.7 | 68.3 | 24.9 | 62.7 | 25.9 | 23.4 | 33.2 |
| OLMo-7B-Instruct | 26.7 | 55.0 | 1015 | 51.7 | 57.1 | 53.1 | 55.9 | 64.6 | 24.7 | 27.3 | 22.9 |
| Qwen1.5-4B-Chat | 24.6 | 57.2 | 988 | 46.0 | 61.4 | 57.2 | 54.9 | 74.1 | 16.5 | 17.3 | 28.6 |
| JetMoE-8B-Chat | 24.3 | 51.6 | - | 46.8 | 58.5 | 27.0 | 86.2 | 68.4 | 19.2 | 25.5 | 11.5 |
| MPT-7B-Chat | 23.8 | 43.8 | 927 | 50.2 | 37.8 | 50.0 | 25.6 | 36.3 | 17.5 | 24.7 | 31.0 |
The evaluation results of chat and base models on MixEval, MixEval-Hard, and their subsplits. The best-performing model in each category is in-bold, and the second best is underlined. *: results provided by the authors.